Comparative evaluation of SPARQL-Generate and RML (old version of SPARQL-Generate)
This comparative evaluation has been conducted for our submission at ESWC 2017 titled: A SPARQL extension for generating RDF from heterogeneous formats.
It evaluates on the performances of the reference implementations of SPARQL-Generate and RML, which are sparql-generate-jena, and RML-Processor respectively.
Documents
We chose to focus on a very simple transformation from CSV documents generated by GenerateData.com to RDF. As an example, document persons.csv contains 100 rows of data.
Archive documents.zip contains CSV documents containing 100, 1000, 5000, 10000, 20000, 30000, 40000, 50000, 100000, and 200000 rows.
Transformations
For every row, a few triples with the same subject, fixed predicates, and objects computed from one column, are generated. As an example, document persons.ttl is the RDF Graph that must be generated from the CSV document that contains 100 rows.
The transformation is equivalently specified:
- as a SPARQL-Generate query in simple.rqg;
- as a RML mapping document in simple.ttl.
Experiment
Java project project.zip contains a Java project that measures the transformation duration for these different CSV documents using sparql-generate-jena, and RML-Processor. At the root of the Java project, file readme.md contains the instructions to reproduce the experiments.
Results
The following figures depict the results in normal, and log-log scale.
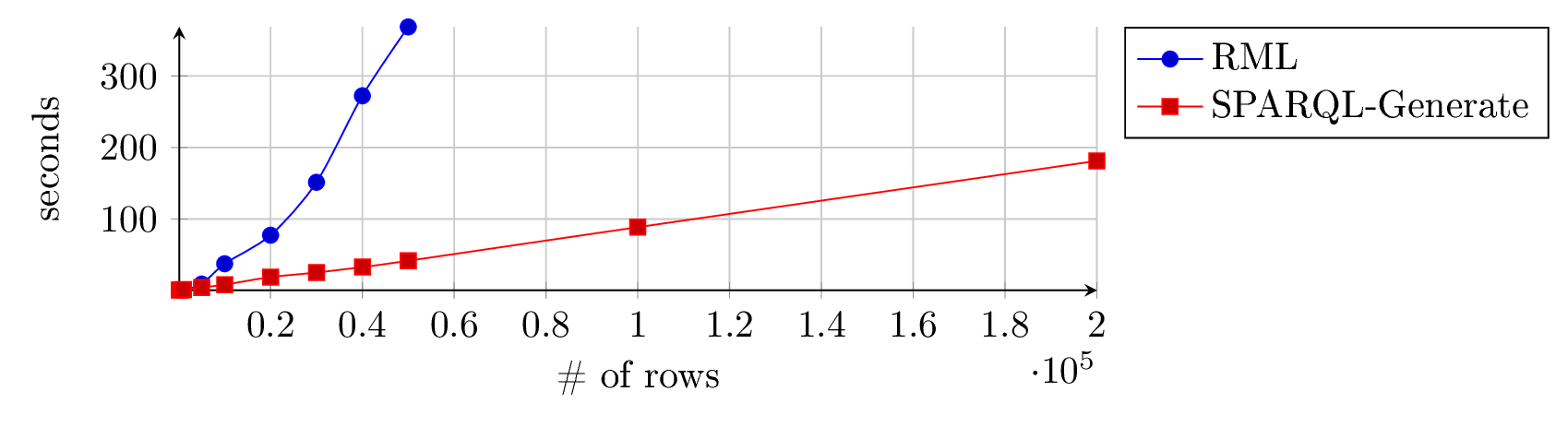
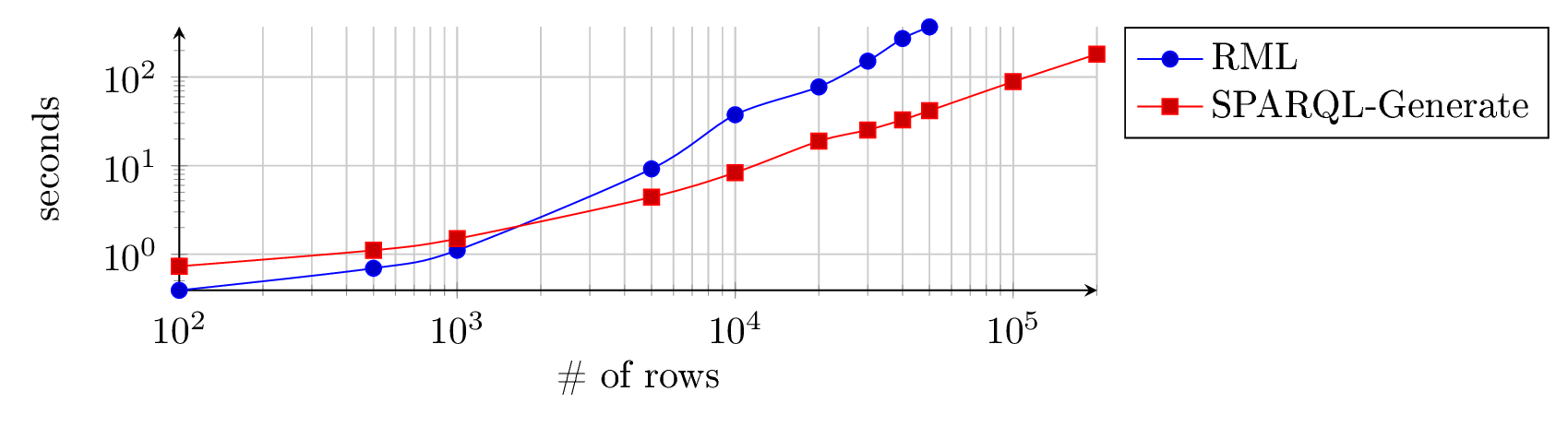
These results show that for this simple transformation, the execution time with sparql-generate-jena becomes faster than RML-Processor above around 1,500 rows, and linear. It is slightly above 3 min for 20,000 rows for sparql-generate-jena, when RML-Processor takes more than 6 min for 5,000 rows. Granted, comparing implementations does not necessarily highlight the true qualities of the approaches since optimizations, better choices of software libraries, and so on, could dramatically impact the results.